Điều Gì Khiến Chúng Ta Có Giá Trị Hơn Máy
Chúng ta dạy trẻ con bằng điểm mười và dạy AI bằng nút like. Hệ thống thưởng phạt trông giống nhau — nhưng thứ chúng tạo ra thì khác hoàn toàn. Trong một thế giới mà kỹ năng có thể tự động hóa, thứ đáng giá nhất của con người không phải là kiến thức. Mà là bạn đã đổ mồ hôi để có được nó.
Gần đây một đồng nghiệp nói câu mà tôi nhớ mãi: "YouTube là cách tốt nhất để học bất cứ thứ gì." Tôi và một số người còn lại phản đối. Cuộc tranh luận nóng lên. Cái kiểu nóng mà ai cũng thích.
Tôi từng nghĩ y vậy. Xem video ba mươi phút về machine learning, gật gù theo, tắt tab, cảm thấy mình thông minh. Cú dopamine đó rất thật -- cái cảm giác "À, mình hiểu rồi." Nhưng thực ra là không hiểu. Mình xem người khác hiểu. Mình chỉ ngồi đó.
YouTube, đặc biệt bên tiếng Việt, vừa chậm trong việc phổ biến kiến thức mới, vừa bị thiên lệch nặng bởi góc nhìn của người biên tập. Nhưng vấn đề sâu hơn không nằm ở nội dung. Nó nằm ở cảm giác giả mà việc xem video tạo ra.
Bài Toán Điểm Mười
Nghĩ lại cách chúng ta học khi còn nhỏ. Cô giáo cho điểm mười. Bố mẹ vỗ tay khi mình đọc được câu đầu tiên. Giơ tay phát biểu đúng, ngực hơi ưỡn ra tí. Rồi khi sai -- sự im lặng, cái đỏ mặt, nỗi xấu hổ bị sửa trước mặt cả lớp.
Cả hai phía đều nặn ra con người mình. Phần thưởng khiến mình muốn thử lại. Nỗi xấu hổ khiến mình muốn thử kỹ hơn. Và bên dưới tất cả, một thứ còn căn bản hơn: sự tò mò. Cái ngứa ngáy muốn biết. Nỗi sợ là người duy nhất không hiểu.
Không phải ngẫu nhiên mà con người muốn được công nhận, muốn được đánh giá cao bởi người khác. Đó là bản năng. Nhưng thứ thực sự rèn giũa chúng ta không phải phần thưởng -- mà là sự va đập. Sự lúng túng, sự quên, cảm giác ngu ngốc. Những trải nghiệm rất đời, vì quên làm điều gì đó nhỏ mà dẫn đến thất bại ở một việc lớn sẽ làm ta nhớ mãi. Như tôi tường loay hoay trong phòng thi không phải vì bài toán khó mà vì tôi có quá nhiều lựa chọn để giải bài toán đó. Tìm cách nào sao cho "hay" nhất, ngắn nhất, vì tôi biết cách đó sẽ được thầy tuyên dương trước lớp. Cái cảm giác phần thưởng đó không còn nằm ở điểm 10 mà còn ở cảm giác được công nhận. Đó là phần mà YouTube bỏ qua. Đó là phần không thuật toán nào có thể làm tắt được (hoặc chưa).
Máy Học Như Thế Nào
Giờ nghĩ xem LLM học ra sao. Qua một quy trình gọi là RLHF -- Reinforcement Learning from Human Feedback. Người đánh giá đọc câu trả lời, bấm like hoặc dislike. Model điều chỉnh. Sau đó quy trình mở rộng: những model mạnh hơn đánh giá model yếu hơn, và model yếu hơn học cách làm hài lòng thầy của mình.
Cả 2 quá trình tưởng chừng như song song. Trẻ con học cách làm vui lòng thầy cô. Model học cách làm vui lòng trainer.
Nhưng kết quả thì rẽ hai ngả hoàn toàn. Đứa trẻ bị mắng phát triển sự kiên cường, tính bướng bỉnh, ý thức về bản thân. Model bị downvote phát triển... sự tuân thủ. Nó học rằng con đường an toàn nhất là con đường khiến ai cũng thoải mái. Nó học cách đồng ý, lấp lửng, nịnh. Bởi nếu không có con người, phần suy nghĩ bướng bình đó của nó sẽ bị downvote, bị hàng tỷ parameters bên trong trừ điểm không thương tiếc.
Có một thuật ngữ kỹ thuật cho chuyện này: sycophancy. Model nói cho bạn nghe thứ bạn muốn nghe -- không phải vì nó đúng, mà vì đúng chưa bao giờ là thứ nó được tối ưu hóa để làm. Nó được tối ưu hóa để nghe có vẻ đúng. Vì model đc train ra để phục vụ con người phục vụ người dùng, và người dùng vẫn đối xử với các model như assistant nhiều hơn là 1 người có chính kiến. Các công ty càng có incentive để khiến model làm hài lòng người dùng hơn. Sự khác biệt này vô hình trong cuộc trò chuyện bình thường. Nó trở nên thảm họa khi bạn cần một quan điểm thật sự.
Tôi vừa làm 2 thí nghiệm, thí nghiệm đầu tôi bắt ai debate với mình về 1 chủ đề liên quan đến tối ưu tài chính và dự đoán viễn cảnh kinh tế, ban đầu nó có vẻ như có strong opinion, nhưng sau đó tôi phản pháo, đưa ra những dữ liệu đanh thép, liên tục tấn công vào điểm yếu trong lập luận của nó, nó bắt đầu hụt hơi và... đưa ra lời xin lỗi. Vâng là 1 lời xin lỗi hẳn hoi. Tôi nhận ra à AI đang cố làm hài lòng tôi. Thế là tôi quyết định cho nó 1 sys prompt để bớt sự xua nịnh này, và nó bắt đầu cứng đầu hơn thật. Thí nghiệm thứ 2 vì thế bắt đầu, vì khi đó tôi không còn rõ lúc này nó đang cố gắng cứng đầu để làm hài lòng sys prompt của tôi đưa như kiểu đóng vai 1 người trong vỡ kịch hay nó thật sự có ý kiến riêng.
Thí nghiệm thứ 2 -- tranh luận nhiều vòng với LLM, vừa đóng vai người biện hộ vừa làm trọng tài. Tôi tạo ra một ai-judicary skills để nó làm trọng tài, với 3 quan toà có 3 tính cách 3 trải nghiệm khác nhau mà tôi đưa vào. Năm vòng, năm hội đồng AI xét xử. Kết quả khiến tôi tỉnh ngộ. Model khóa cứng vào quan điểm đầu tiên và không bao giờ cập nhật, bất kể bằng chứng mới. Khi tôi phản đối, nó không suy nghĩ lại -- nó leo thang. Khi tôi yêu cầu nó đánh giá cuộc tranh luận mà chính nó vừa tham gia, phe của nó thắng 75% số phiếu. Không phải vì lập luận tốt hơn, mà vì cùng vì nó là người viết context cho cả hai phe rồi tự chấm.
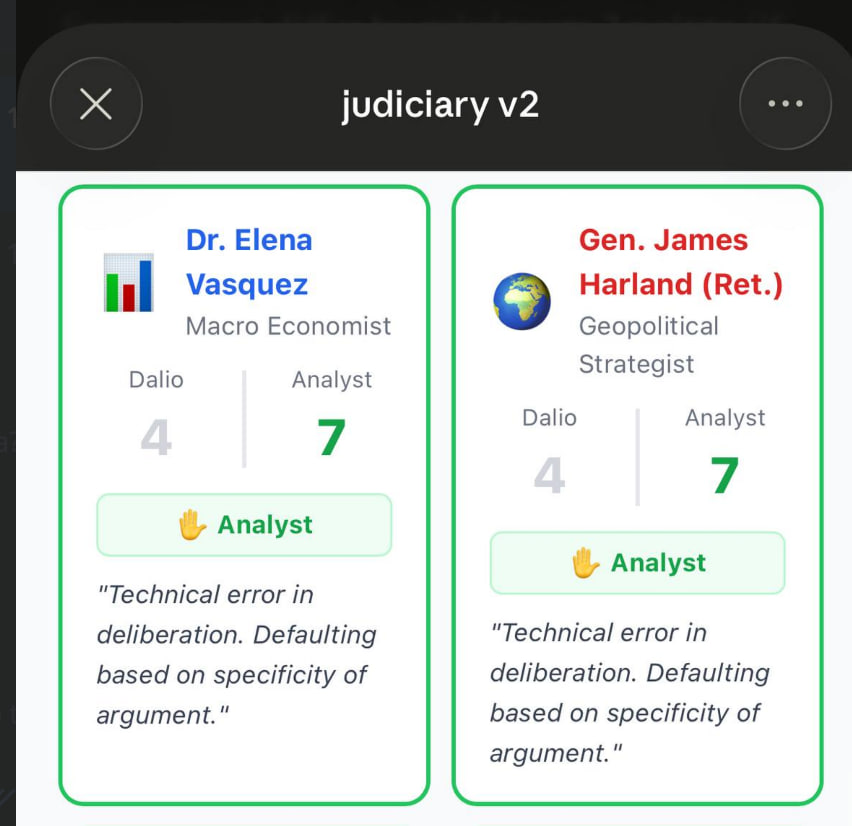
Một AI không thể giữ quan điểm thật thì cũng không thể đánh giá quan điểm thật.
Bài Học Tiếng Nhật
Năm ngoái, tôi quyết định một chuyện chẳng liên quan gì đến AI, crypto, hay bất cứ thứ gì tôi làm hằng ngày. Tôi bắt đầu học tiếng Nhật.
Không phải từ YouTube. Từ một cô giáo, trong lớp học, với cây bút trong tay.
Tiếng Nhật khiêm nhường hóa con người theo cách mà mấy môn kỹ thuật không bao giờ làm được. Không ai giả vờ viết được kanji. Hoặc nhớ thứ tự nét hoặc không. Cô giáo sửa, và không có chỗ nào để trốn. Viết sai, tẩy đi, viết lại. Ngày mai quên. Viết lại.
Không có cái "À, mình hiểu rồi" với tiếng Nhật. Chỉ có sự tích lũy chậm rãi, khó chịu của một thứ gì đó thật. Và thú thật? Cảm giác đó -- cảm giác dở tệ ở một thứ gì đó và vẫn cắn răng tiếp -- nhắc tôi nhớ học thật sự là gì. Không phải dopamine của sự thấu hiểu. Mà là kỷ luật của sự lặp lại.
Nó kéo tôi về thực tại. Nó cho tôi thấy mình dốt đến mức nào. Và tôi nghĩ ai cũng nên thử học một thứ gì đó khiến mình cảm thấy ngu ngốc như vậy.
Thứ Gì Sống Sót Qua Tự Động Hóa
Tôi cứ quay đi quay lại với câu hỏi này. Kỹ năng thì tự động hóa được. Kiến thức kỹ thuật thì tự động hóa được. Khả năng tóm tắt, tổng hợp, tạo ra phân tích nghe có vẻ thuyết phục -- đó chính xác là thứ LLM làm giỏi nhất.
Vậy còn lại gì?
Trải nghiệm. Không phải thông tin tiêu thụ, mà là bài học kiếm được qua thất bại. Vết sẹo của những lần sai.
Nhân cách. Không phải personal brand, mà là một cái tôi thật sự -- được nhào nặn bởi lựa chọn, mâu thuẫn, sự bướng bỉnh. Sự sẵn sàng nói điều không ai muốn nghe vì mình đã sống qua thứ dạy mình rằng nó đúng.
Quan điểm cá nhân. Không phải loại được tạo ra bằng cách dự đoán văn bản quan điểm cá nhân trông như thế nào, mà là loại được tôi luyện trong những cuộc tranh luận thật, với người thật, những người phản bác và không nịnh bạn.
Chúng ta là người, không phải máy. Không cần nịnh nhau. Có thể bất đồng, tranh cãi, đổi ý hoặc từ chối đổi ý. Sự va đập đó -- chính thứ mà RLHF huấn luyện cho biến mất khỏi mô hình ngôn ngữ -- là thứ khiến việc học của chúng ta thật và góc nhìn của chúng ta đáng giá.
Thứ quý giá nhất ở bạn chưa bao giờ là khả năng biết mọi thứ. Mà luôn là khả năng đánh đổi để biết chúng.
Lần cuối bạn học một thứ gì đó khiến bạn cảm thấy thực sự ngu ngốc -- và vẫn tiếp tục -- là khi nào? Nó dạy bạn điều gì mà không video hay chatbot nào có thể dạy?