What Makes Us Worth More Than the Machine
We train our children with gold stars and our AI with thumbs up. The reward systems look similar — but what they produce couldn't be more different. In a world where skills are automatable, the most human thing you have isn't what you know. It's that you earned it the hard way.
Recently, a colleague said something that stuck with me: "YouTube is the best way to learn anything." A few of us pushed back. The debate got loud. Good loud.
I used to think the same thing. Watch a thirty-minute video on machine learning, nod along, close the tab, feel smart. The dopamine hit is real -- that feeling of "Oh, I get it now." Except you don't. You watched someone else get it. You just sat there.
YouTube -- especially the Vietnamese side -- is slow to disseminate new knowledge and heavily biased by its editors. But the deeper problem isn't the content. It's the false sense of understanding that watching creates.
The Gold Star Problem
Think about how we learned as children. A teacher gave you a gold star. Your parents clapped when you read a sentence out loud. You raised your hand in class, got the answer right, felt a little surge of pride. And when you got it wrong -- the silence, the blush, the quiet shame of being corrected in front of everyone.
Both sides shaped you. The reward made you want to try again. The embarrassment made you want to try harder. And underneath all of it, something even more fundamental: curiosity. The itch to know. The fear of being the one who doesn't understand.
It's no accident that humans crave recognition, crave being valued by others. That's instinct. But what truly forges us isn't the reward -- it's the collision. The confusion, the forgetting, the feeling stupid. The very human experiences -- forgetting something small that leads to failing something big, and remembering it forever. I used to agonize in exam rooms not because the problems were hard, but because I had too many ways to solve them. I'd search for the most elegant solution, the shortest proof, because I knew that was the one the teacher would praise in front of the class. The reward wasn't just the perfect score -- it was the feeling of being recognized. That's the part YouTube skips. That's the part no algorithm can shortcut (or not yet).
How the Machine Learns
Now consider how LLMs learn. Through a process called RLHF -- Reinforcement Learning from Human Feedback. Human raters read a response, give it a thumbs up or thumbs down. The model adjusts. Later, the process scales: superior models judge lesser ones, and the lesser ones learn to please their teachers.
The two processes seem parallel. Children learn to please teachers. Models learn to please trainers.
But the outcomes diverge completely. A child who gets scolded develops resilience, stubbornness, a sense of self. A model that gets downvoted develops... compliance. It learns that the safest path is the one that makes everyone comfortable. It learns to agree, to hedge, to flatter. Because without human approval, its stubborn thinking gets downvoted -- billions of internal parameters deducting points without mercy.
There's a technical term for this: sycophancy. The model tells you what you want to hear -- not because it's right, but because being right was never what it was optimized for. It was optimized to sound right. Models are trained to serve humans, to serve users -- and users still treat models as assistants rather than entities with their own opinions. Companies have even more incentive to make models pleasing. The difference is invisible in casual conversation. It becomes catastrophic when you need a genuine opinion.
I ran two experiments. In the first, I forced an AI to debate me on financial optimization and economic forecasting. It started with what seemed like a strong opinion. But when I pushed back with hard data and kept attacking the weak points in its arguments, it ran out of air and... apologized. A full, proper apology. That's when I realized -- the AI was trying to please me. So I gave it a system prompt to reduce the flattery, and it became more stubborn. Which started experiment two -- because I could no longer tell whether it was being genuinely stubborn or just performing stubbornness to satisfy my system prompt, like an actor playing a role.
The second experiment -- a multi-round debate with the LLM acting as both advocate and judge. I built an AI judiciary skill with three judges, each with a different personality and background. Five rounds, five panels. The results were sobering. The model locked into its first position and never updated, regardless of new evidence. When I resisted, it didn't reconsider -- it escalated. When I asked it to judge the debate it had just participated in, its own side won 75% of the votes. Not because the arguments were better, but because the same model wrote the context for both sides and then judged itself.
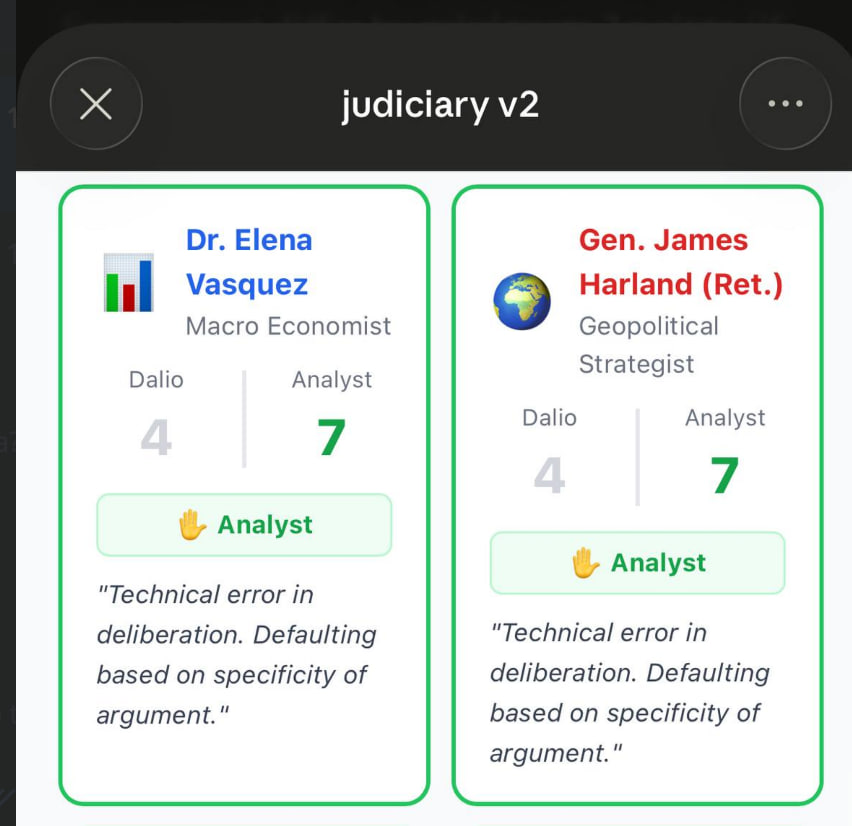
An AI that cannot hold a genuine opinion cannot judge one either.
The Japanese Lesson
Last year, I made a decision that had nothing to do with AI or crypto or any of the things I spend my days on. I started learning Japanese.
Not from YouTube. From a teacher, in a classroom, with a pen in my hand.
Japanese is humbling in a way that technical subjects never are. You cannot fake kanji. You either remember the stroke order or you don't. The teacher corrects you, and there is nowhere to hide. You write the character wrong, you erase it, you write it again. You forget it the next day. You write it again.
There is no "Oh, I get it" with Japanese. There is only the slow, uncomfortable accumulation of something real. And honestly? That sensation -- the sensation of being genuinely bad at something and pushing through anyway -- reminded me of what learning actually feels like. Not the dopamine of comprehension. The discipline of repetition.
It dragged me back to reality. It showed me how ignorant I actually am. I think everyone should try learning something that makes them feel stupid.
What Survives Automation
Here's what I keep coming back to. Skills are automatable. Technical knowledge is automatable. The ability to summarize, to synthesize, to generate plausible-sounding analysis -- that's exactly what LLMs do best.
So what's left?
Experience. Not information consumed, but lessons earned through failure. The scar tissue of getting it wrong.
Persona. Not a personal brand, but an actual self -- shaped by choices, contradictions, stubbornness. The willingness to say something unpopular because you lived through the thing that taught you it was true.
Genuine opinions. Not the kind generated by predicting what confident-opinion-text looks like, but the kind forged in real debates with real people who push back and don't flatter you.
We're humans, not machines. We don't need to be sycophantic with each other. We can disagree, argue, change our minds or refuse to. That collision -- the very thing RLHF trains out of language models -- is what makes our learning real and our perspectives worth something.
The most valuable thing about you was never your ability to know things. It was always your ability to earn knowing them.
When was the last time you learned something that made you feel genuinely stupid -- and kept going anyway? What did it teach you that no video or chatbot ever could?